Data Quality et intelligence artificielle sous Solvabilité 2 : vers un pilotage prudentiel augmenté
1. Introduction
Pourquoi la QDD est désormais un sujet Data & IA ?
Historiquement, la Qualité des Données (QDD) a été abordée sous l’angle réglementaire avec Solvabilité 2, à travers des principes généraux puis des précisions apportées par le règlement délégué et, plus récemment, la notice ACPR de novembre 2023. L’objectif était d’assurer la fiabilité des données servant aux calculs prudentiels (provisions techniques, SCR, MCR, modèle interne).
Les critères classiques (exhaustivité, exactitude, pertinence) encadraient cette exigence, principalement via des processus de contrôle interne, des dispositifs de gouvernance et des outils documentaires (répertoire, cartographie, indicateurs de QDD).
Cependant, l’évolution des environnements technologiques et des usages des données transforme profondément la QDD en un enjeu Data et IA :
-
Explosion des volumes et de la diversité des données : les organismes d’assurance ne se limitent plus aux seules données comptables et prudentielles. Ils intègrent désormais des données massives issues de systèmes opérationnels, de partenaires externes, d’open data, ou encore de données non structurées (textes, images, signaux IoT[1]). Cette diversité complexifie les contrôles manuels traditionnels et nécessite des outils de data engineering et de machine learning capables d’automatiser la détection d’erreurs et d’anomalies.
- Renforcement de la traçabilité et du lignage : dans le cadre de Solvabilité 2 (article 82 de la Directive et Règlement délégué 2015/35, articles 262-264), les assureurs doivent garantir la qualité, l’exhaustivité, la précision et la traçabilité des données utilisées pour les calculs prudentiels et les reportings réglementaires. Cette exigence de transparence impose aujourd’hui la mise en place de solutions technologiques avancées permettant de suivre le cycle de vie des données (data lineage). Les plateformes de type data lakehouse et les outils de gouvernance (catalogues de données, métadonnées enrichies) utilisent déjà des techniques d’IA pour cartographier et classer automatiquement les flux de données.
- Utilisation croissante de l’IA dans les processus métier : les modèles prédictifs (pricing, détection de fraude, prévision de sinistralité, calculs prudentiels avancés) reposent sur la qualité intrinsèque des données. Une donnée biaisée, incomplète ou bruitée induit un risque accru de « modèle non fiable », ce qui rejoint directement les préoccupations prudentielles de l’ACPR. La QDD devient ainsi un prérequis à la fiabilité des algorithmes d’IA utilisés en assurance.
-
Automatisation et monitoring en continu : la QDD n’est plus un exercice ponctuel mais un processus continu. Les organisations déploient des solutions de data quality monitoring intégrant des règles métiers, des seuils de tolérance, mais aussi des approches d’IA (apprentissage supervisé ou non supervisé) pour détecter en temps réel les anomalies, dérives ou valeurs aberrantes.
La qualité des données (QDD) n’est plus seulement un exercice de conformité. Elle est désormais un pilier de la stratégie data et IA des assureurs, garantissant à la fois :
- la robustesse des calculs prudentiels,
- la fiabilité des modèles prédictifs,
- la maîtrise des risques liés aux données externes,
- et la capacité à répondre aux nouvelles exigences de transparence et de traçabilité des régulateurs.
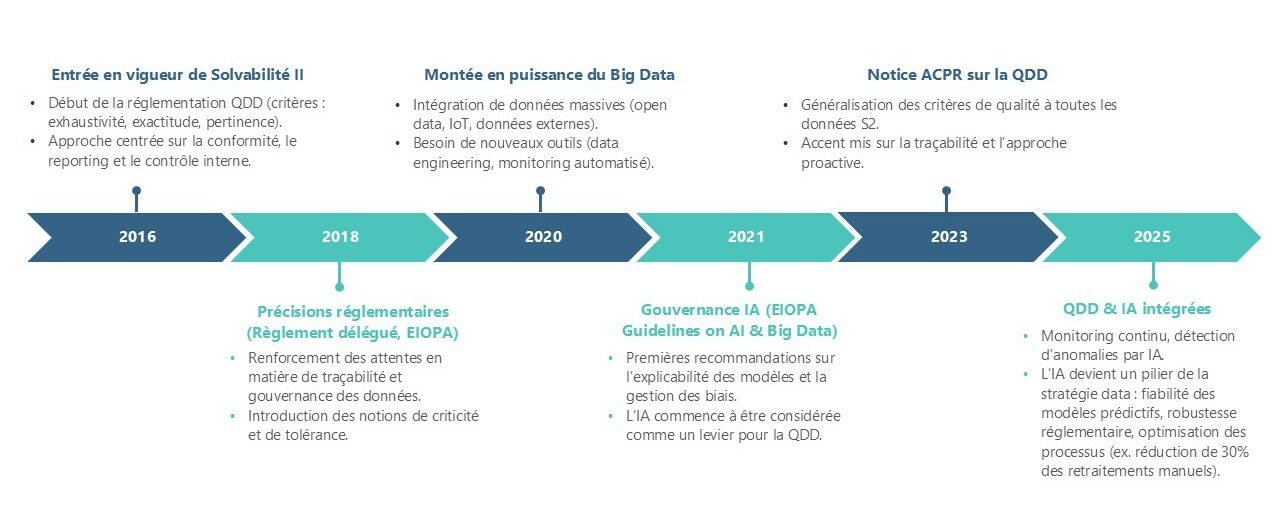
Figure 1 : Évolution de la Qualité des Données en Assurance : de Solvabilité II à l’ère de l’IA
2. Principe méthodologique de la QDD sous Solvabilité II
3. Apport concret de l’IA à la Data Quality sous Solvabilité II
Le rapport de la Commission introduit des modifications ciblées du CRR (règlement sur les exigences de fonds propres) et de l’acte délégué sur le LCR (ratio de liquidité à court terme). Il vise à réduire les écarts injustifiés entre les méthodes internes (SEC-IRBA) et standardisées (SEC-SA) de calcul des fonds propres et à encourager la participation des banques de taille moyenne sur le marché de la titrisation. Pour cela, deux leviers sont ciblés :
3.1. Identification des données critiques
3.1. Identification des données critiques
3.3. Scoring dynamique & prédictif
Ces signaux d’alerte précoce aident donc à déclencher des actions correctives ciblées (revue, nettoyage, recalcul) avant que la non-qualité n’affecte les résultats prudentiels.
Interprétabilité et gouvernance
Dans un contexte réglementé, il ne suffit pas de détecter les anomalies : il faut aussi expliquer pourquoi le modèle les a détectées.
C’est ce que l’on appelle l’interprétabilité : la capacité à comprendre et justifier les décisions ou alertes émises par un algorithme.
Pour les modèles complexes (ex. réseaux de neurones, ensembles d’arbres), des techniques d’explicabilité telles que SHAP (SHapley Additive exPlanations) ou LIME (Local Interpretable Model-agnostic Explanations) permettent de :
Ainsi, le scoring prédictif et interprétable devient un levier de pilotage à double finalité :
4. Bénéfices attendus
Références
[1] ACPR - Notice « Exigences en matière de qualité des données pour les organismes et groupes d’assurance soumis à la Directive Solvabilité 2 », nov. 2023 (PDF). ACPR
[2] Lundberg & Lee (2017) - SHAP: A Unified Approach to Interpreting Model Predictions (NeurIPS paper) - pour feature importance / explainability. proceedings.neurips.cc
[3] Anomaly detection (Isolation Forest, Autoencoders) — articles et revues récentes (ex. recherches 2024–2025 sur détection en assurance/healthcare). Taylor & Francis Online+1
[4] Christen, P. (2012). Data Matching: Concepts and Techniques for Record Linkage, Entity Resolution, and Duplicate Detection. Springer.
[5] Devlin, J., Chang, M.-W., Lee, K., & Toutanova, K. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of NAACL-HLT 2019.
Auteurs

